Our Product
Learn more about our product's inner workings.
Our product's dataset contains approximately 500,000 tweets published between 2022-2023 from 485 US Congress members. To collect the latest 100 tweets per politician, we created pipelines to extract this data using the Twitter API, and for historical tweet data, we used our partner Torch’s platform to extract tweets in CSV files. The politicians’ metadata including their Twitter handle, party affiliation, political office, and state/district was pulled from secondary sources including Press Gallery House and UC San Diego. Below is an example of a tweet that was obtained from the data sources:
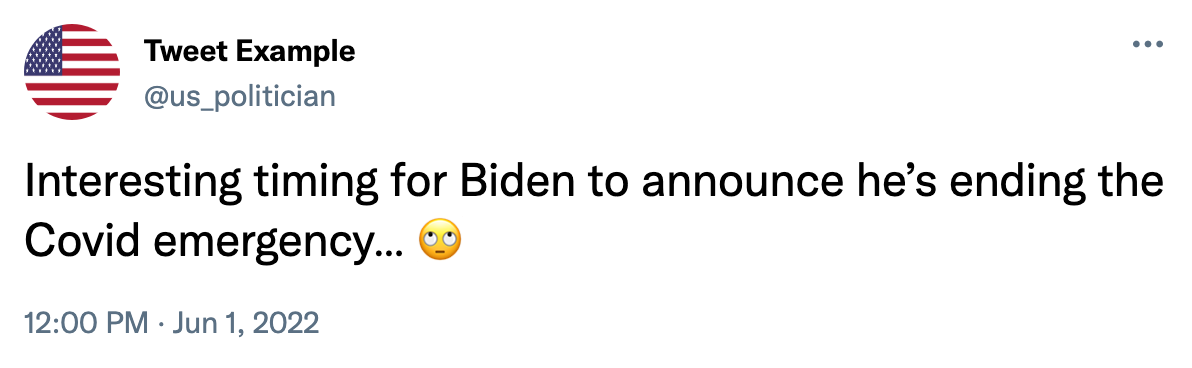
Text from tweets was cleaned up in order to run inside of the pre-trained models. Non-standard symbols were trimmed and content such as links and common stopwords were removed from the corpus. Lastly, different variations of the same word were lemmatized so that they were evaluated the same way in the models.
Ultimately, the cleansed version of the tweet example above would look like: [“interesting”, “time”, “biden”, “announce”, “ending”, “covid”, “emergency”]
Some initial observations were drawn upon reviewing the data. The average politician in our dataset produced 630 tweets per year, of which the most popular themes were healthcare, gun violence, energy, inflation, and infrastructure. In terms of who was referenced within the tweets, the most common subjects were the President of the US, the members from the partisan left and right wing, and media outlets like Fox News.
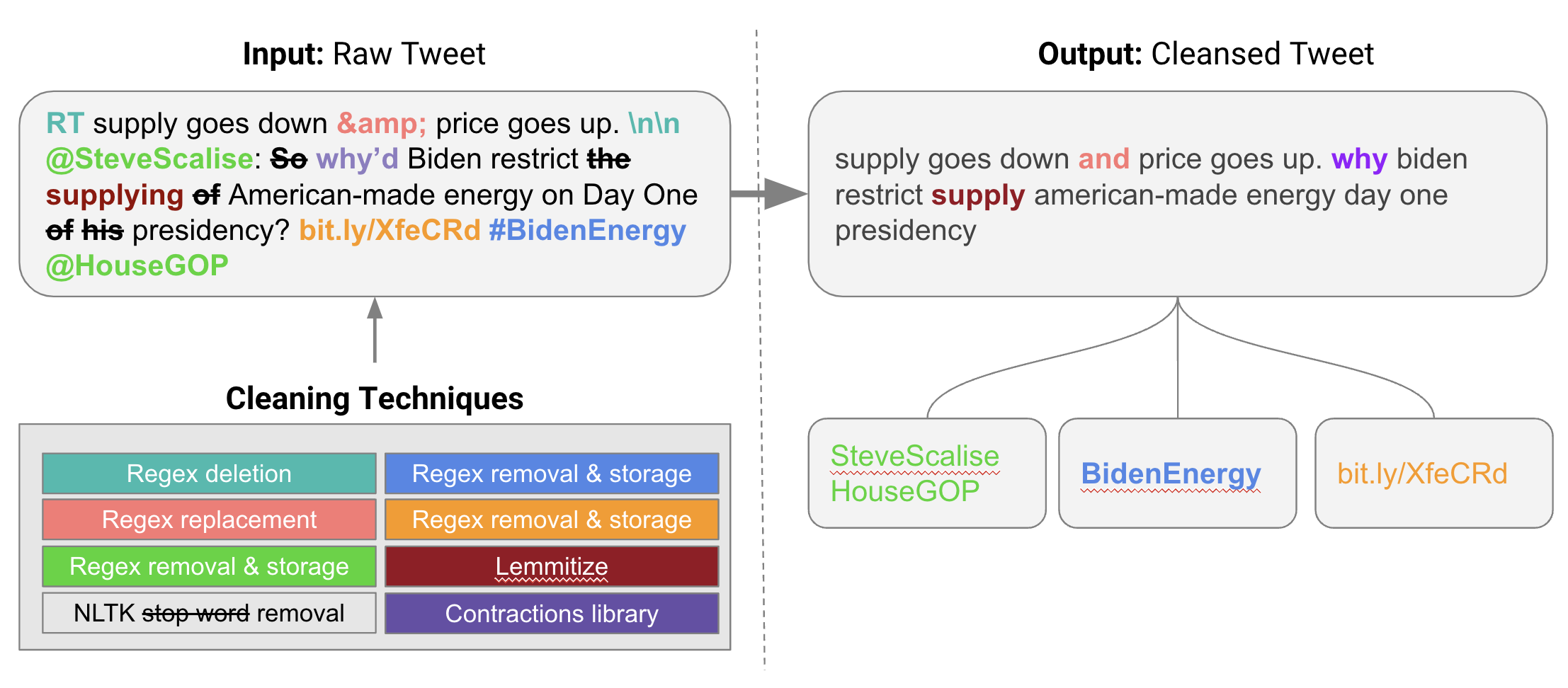
We have two parts to our modeling: 1) scoring text with existing research models; 2) aggregating scored text to evaluate each Twitter user. We incorporated existing research on detecting truthfulness and sentiment with large language models into our pipeline to score tweet content. We used a total of eight pre-built models including three models for detecting the truthfulness of tweets and five sentiment models for detecting the emotions evoked by tweets:
- Long Short-Term Memory (LSTM): Truth
- Dense Layer: Truth
- Cardiff Model: Irony
- Cardiff Model: Hate
- Cardiff Model: Offensive
- Cardiff Model: Real
- Cardiff Model: Joy
- Cardiff Model: Anger
Each model was trained on various datasets. For example, the 5 sentiment models were trained using the following datasets:
To create a composite score for each user, all tweets are scored, scaled using a standard scaler, and added together. For example, starting with 8 different scores for each tweet, we scale them so that 0 is neutral, positive is good behavior, and negative is bad behavior. These 8 scaled model scores are summed together for a composite score for each tweet of a particular user.
Then, we calculate the average composite tweet score for each user to arrive at an aggregated score. This final aggregated score represents how susceptible that individual Twitter user is to spreading disinformation.
Check out the "Our Models" section to learn more about each individual model.
Given that many of our models assess sentiment, which is largely subjective, it was quite challenging to assess model performance objectively. Even for a matter such as truth, the difficulty lies in how to rate statements that merely constitute an opinion, or are roughly true but contain a small falsehood. Thus, aside from confirming the validity of models within an individual context by referencing the sources they came from, human evaluation was another approach taken to determine how agreeable the model outputs would be, on average, in comparison to a human observer.
In general, our chosen models had promising results in terms of sentiment and text analysis, and also served to demonstrate potential shortcomings and challenges to overcome in their next iterations. While they overall did well in detecting the negative sentiments of hate, irony, and offensiveness within tweets, truth detection was a much more difficult problem. When comparing human ratings to their equivalent model outputs, the model scores differed from their human counterparts by an average of 15% in the sentiment-based models, but a whopping 52% in the truth-based models.
These numerical figures should be taken with a grain of salt, however. Even between human evaluators, there was a measured difference of 3% and 17%, respectively, between different human ratings. Thus, part of this discrepancy can be explained as the objective difficulty in rating the truthiness of many short statements (evident in the person-person score differences), while another part could potentially be chalked up to the limited body of text that is present in tweets. It appears that certain models may rely on a larger corpus of text in order to detect idiosyncrasies and false statements.
Interestingly, the truth sentiment graphs largely seemed to agree with one another, which suggests that they might be “thinking” the same way. Further steps to improve the model may constitute undertakings such as integrating the text or image within links as an input, using retweets, likes, and comments to add context to individual scores, and continuing the cluster analysis in model combination to determine if any interesting groups of users emerge.
Our product's data pipeline includes the following components:
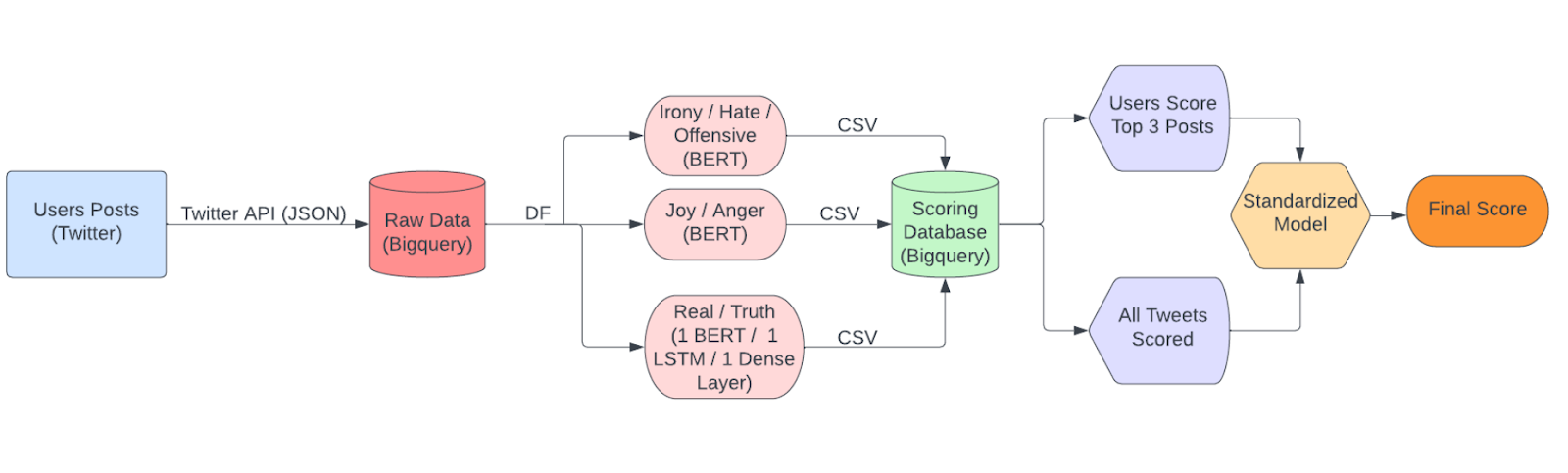
Here's how the data pipeline works:
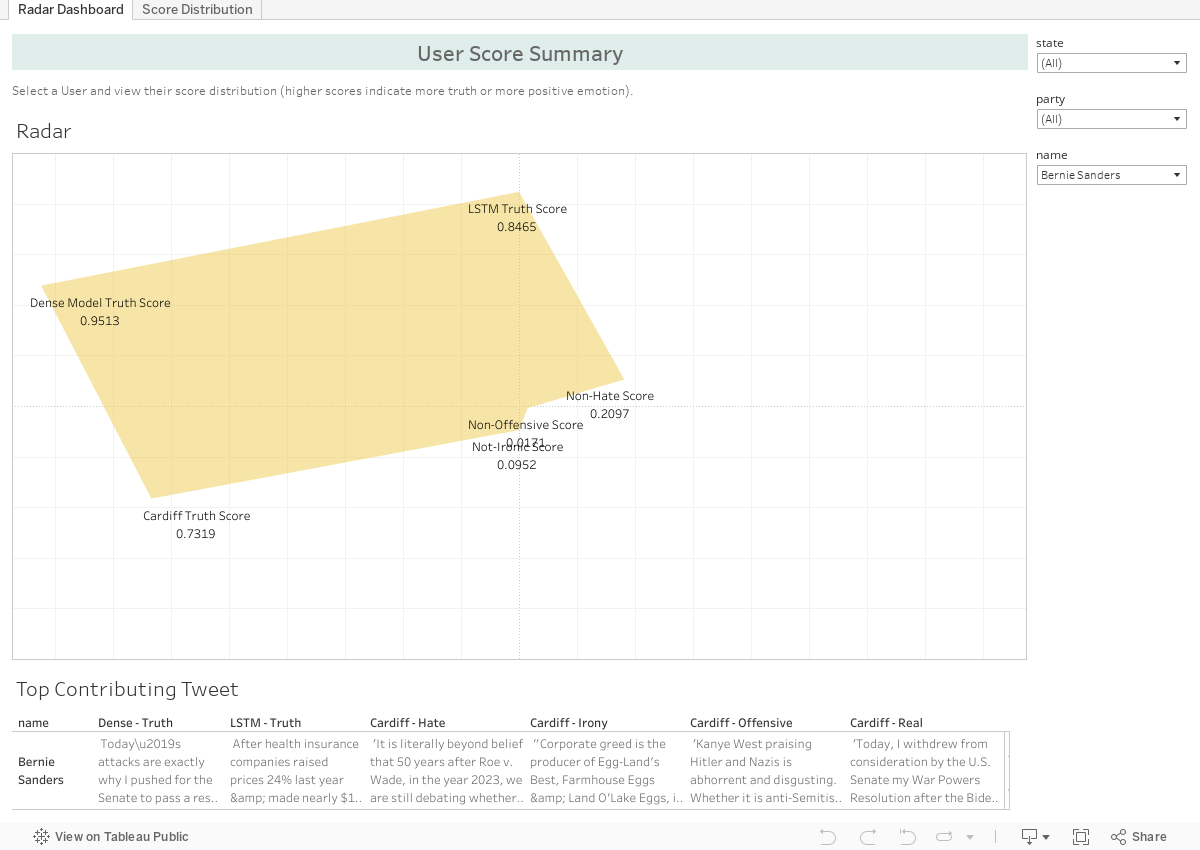
How to Interpret the Radar Plot
The radar plot shows the performance of six models for a selected user. The scores represent the politician's rank, also called percentile, compared to other politicians across six domains of interest. The models initially scored politicians on a scale from 0 to 1 and ranked the results to obtain a value. The value indicates how the user performs compared to others. For example, a score of 93% in one category suggests that the user performs better than 93% of other users but worse than 7% (100 - 93 = 7) of users. A larger graph with a hexagonal shape indicates better performance compared to other users and suggests the user has an overall positive influence on the Twitter network.
In summary, the radar plot provides a representation of a politician's relative performance across multiple domains of interest and visualizes an overall pattern of behavior of a user on Twitter.
How to Interpret the Distribution Plot
The distribution plot displays the distribution of values obtained/calculated from the last 100 tweets for the selected politician. The x-axis indicates the tweet’s rank, also called percentile, for a selected model/score. The y-axis represents the count of tweets per percentile bucket. A high peak approaching the 90th percentile suggests that a significant number of the politician's tweets outperform those of other politicians in the selected domain of interest.
In summary, the distribution plot provides a representation of a politician's tweet performance in a domain for a given model. It indicates whether their tweets perform better or worse than those of other users.









